Waveform Autoencoder Synthesizer
Code: https://github.com/jcstucki/Single-Cycle-Waveform-Autoencoder
What is this?
This was a project for Digital Musical Instrument Design (DMID) at Northwestern University. This is a neural network autoencoder that encodes 4000 Adventure Kid Waveforms into a two dimensional latent space. Then, during inference time, the latent space is interpolated through with the mouse in order to create new combinations of existing waveforms, which are then played back in real time. The outcome is an instrument with dynamic timbre and pitch control.
How does this work?
A neural network autoencoder is created in tensorflow, and trained on 4000 individual single-cycle waveforms from the website listed above. The training process is done within a jupyter notebook. The architecture of the network is a standard densely connected autoencoder, with the exception of the activation function of the last layer of the encoder being a sigmoid function to ensure the encoded latent representation remains in the range of (0-1). A future version would also use 1D convolutional layers instead of dense layers, as well as batch and layer normalization to assist with keeping the latent representations within the [0-1] range. Both the encoder and decoder are then saved as .h5 tensorflow model files.

Latent Space
A visualization of the 4000 encoded waveforms in 2D latent space.
Inference
For live inference, we load the saved models into a running p5 window. The p5 script’s 2D grid acts as the two-dimensional latent-space for the autoencoder. The X/Y position of the mouse cursor over the p5 window is normalized between (0-1) to equal the sigmoid (0-1) mapping of the autoencoder. The normalized position is then fed into the decoder half of the network in order to upsample the latent variables to the dimension of the original waveforms (in this case, a tensor of shape (1,600)). The result, is a “new” waveform. This waveform is then displayed in the p5 window for visualization purposes.
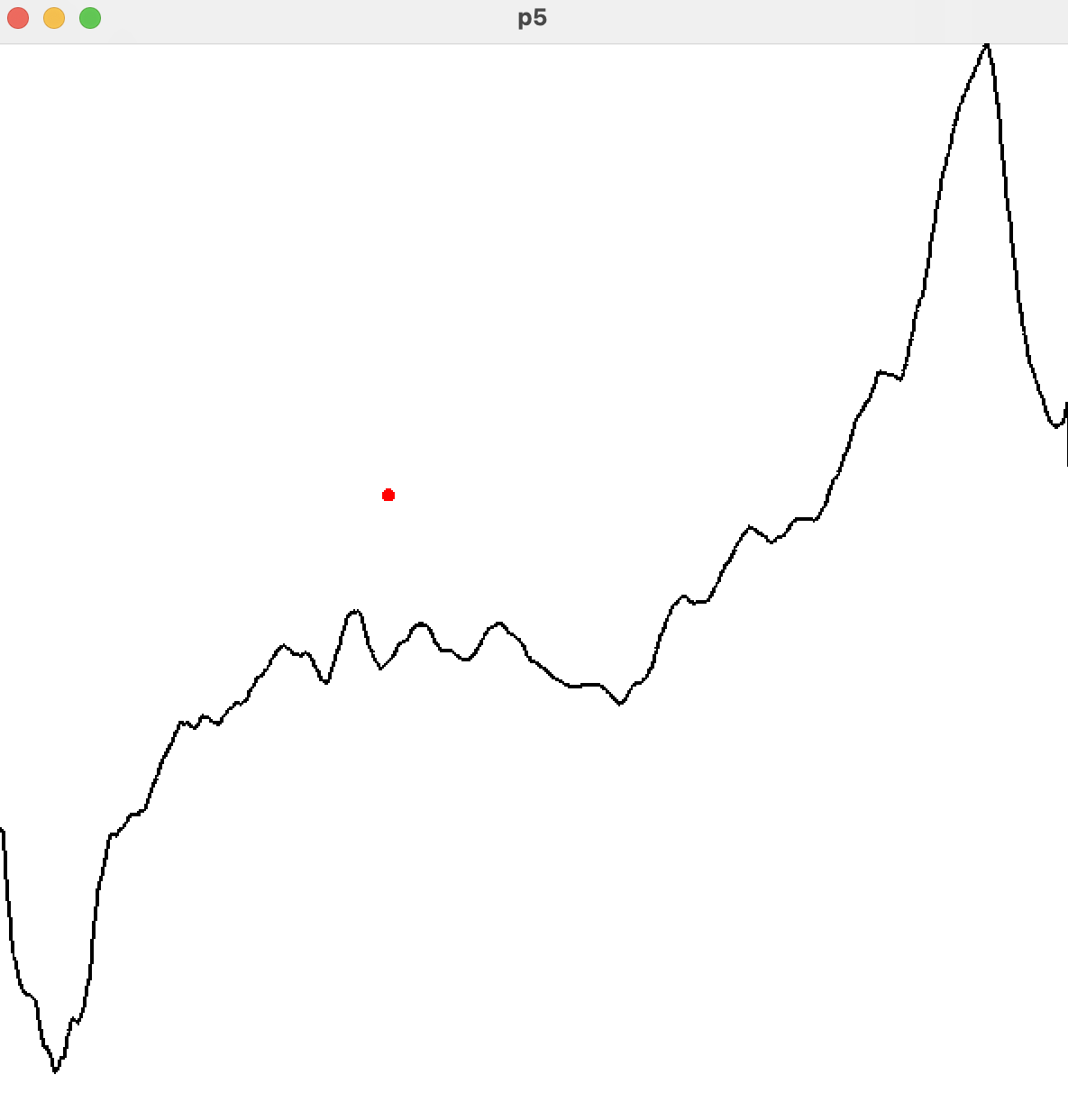
Mouse Interpolation
The red dot represents the mouse position within the latent space, while the black line is the output of the neural network.
To sonify the waveform created in the above process, the created tensor is placed into a python dictionary by index. The dictionary is then dumped to json text, and sent via socket.io to a running node.js server. The server’s architecture is fairly simple, and could be created in either python or node.js. Its purpose, to listen for any incoming dictionaries from clients, and re-broadcast them to any other connected clients. This rebroadcasting is important due to the architecture of the sonification process, which is completed in MaxMSP. Max does not natively run python, but does run node.js via the node.script object. This allows for a node.js socket.io client to be running in real time within Max. This node.js client is listening for any dictionary messages from the running node.js server, completing the connection between the running python p5 script and MaxMSP!
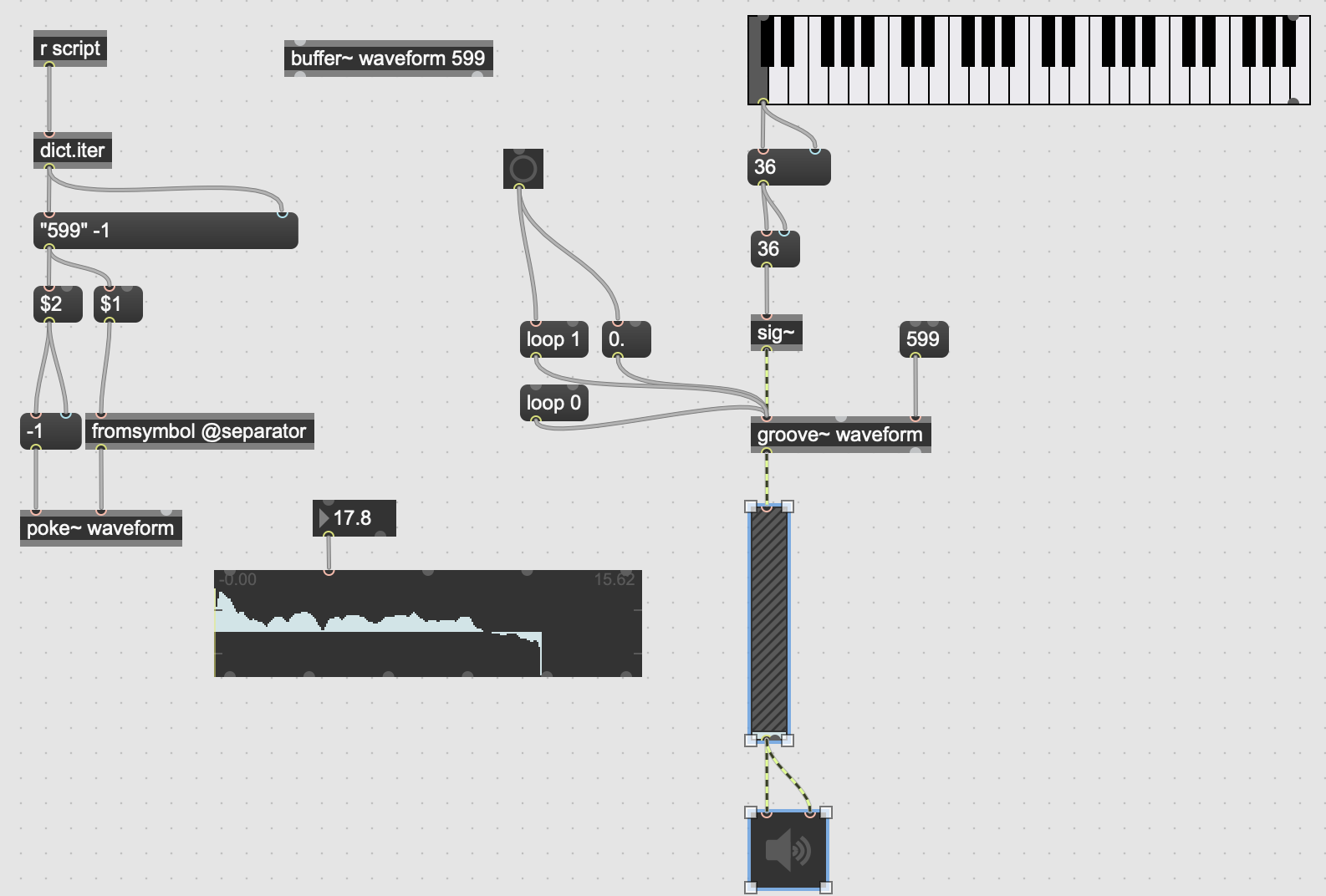
The Max Patch with the new waveform loaded into a buffer~ object using poke~
The final sonification process is done using MaxMSP’s poke~ and buffer~ objects. poke~ allows data to be read into a buffer via a “signal” that increments by 1, which is equivalent to our dictionary’s index. So, writing to the created buffer~ is straightforward. The buffer is then looped through on a repeating basis, just as one would play any single-cycle waveform. Pitch control is added via groove~, and the output is sent to the Digital-to-Analog converter to be heard!
Supplemental Questions
Why wasn’t a Variational Autoencoder used? Doesn’t that make more sense?
Initially, the plan was to use a VAE to do the encoding, but due to the tricky and more complex nature of creating and training a VAE, the output waveforms were not very great. A future version of this project may revisit the VAE architecture. The sigmoid function was used “in place” of a VAE to confine the data to a pseudo-uniform distribution.
Why doesn’t the autoencoder produce waveforms that look like the original data?
This could be due to many reasons, including: not enough training time, poor network architecture, not enough training data, etc.
Would you consider this project a success?
Yes! Even though the waveforms are very distorted and do not look anything like the input data, the basic data flow and structure shows that this is a viable method for new waveform creation, and with modification, could become a powerful new method for synthesis.
Bugs:
Look at order of magnitude between points in latent space, seems off by orders of magnitude for a distribution.
Index offset issues
Index clipping
Max doesn’t play the whole waveform.
Either the p5 display is backwards or the max buffer is backwards, I think it’s the p5 display.
Thoughts
We can use a joystick style controller to move through the waveforms.
This can be used for any number of waveforms in the dataset, since we want to learn the waveforms themselves.
It provides a sort of waveform filtering effect.
In it’s current state, it sounds very annoying…